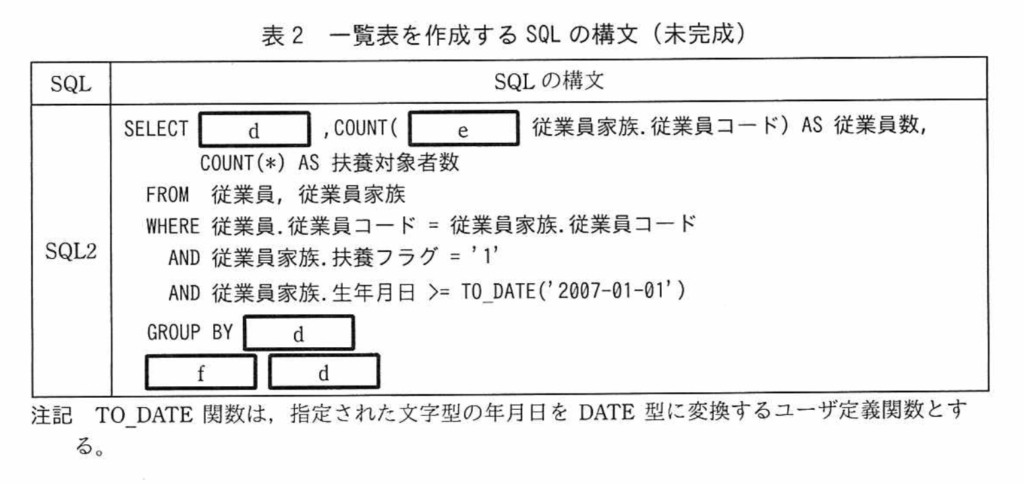
【R06PM1問2】<SQL2> SQL2は、エリアごとの在籍者増減数を求めるSQLだ。 ①で、’入室’状態の人を1とし、その合計を求め、 ②の’退室’状態の人の合計を①から減算し、在籍者増減数を算出している。 ①【a;SUM】(CASE WHEN 【b;入退室ログ=’1’】 THEN 1 ELSE 0 ) ②ー 【a;SUM】(CASE WHEN 【b;入退室ログ=’0’】 THEN 1 ELSE 0 ) AS 在籍者増減数
<SQL5> SQL5は、入室している従業員のログIDのエリアコードを取得するSQLである。 「CASE WHEN 【b;入退室ログ=’1’】THEN エリアコードELSE ‘9999’ END AS エリアコード」で’入室’状態の時、エリアコードを挿入、’退室’の時、’9999’を挿入し、それらをエリアコードと呼んでいる。 また、「WHERE ログID=:HCURRENTID」でログIDが現時点でのログIDに限定している。 SELECT CASE WHEN 【b;入退室ログ=’1’】THEN エリアコード ELSE ‘9999’ END AS エリアコード FROM 入退室ログ WHERE ログID=:HCURRENTID
【R06PM1問2】③
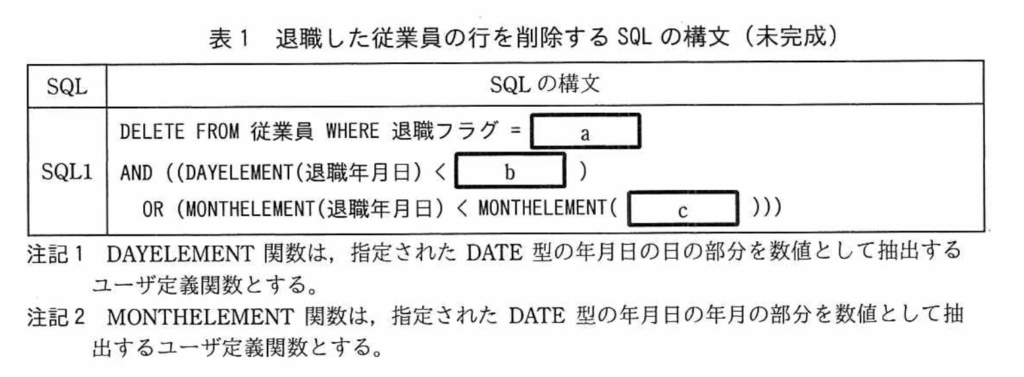
①WHERE 従業員番号 BETWEEN 【e;:HTARGETID】 AND 【f;:HENDID】 ②AND 年月日 BETWEEN :HBEGINDAY AND :HENDDAY ③AND 上長承認=’Y’ AND 監査結果 【g;IS NULL】 ④ORDER BY 【h;従業員番号】,年月日
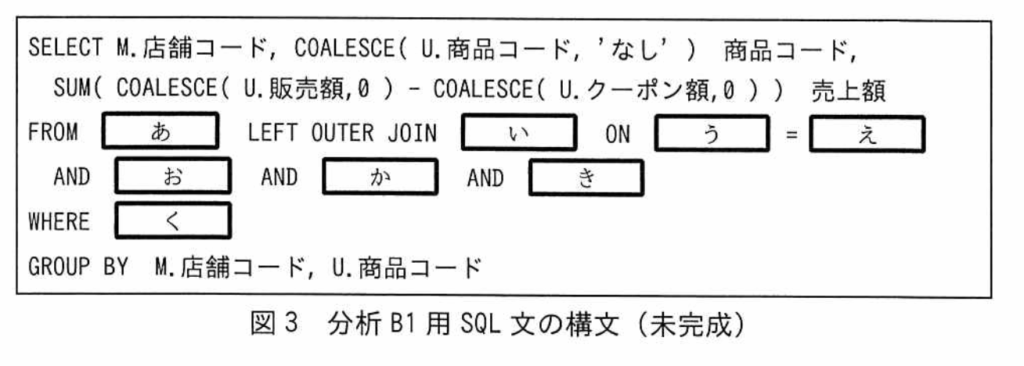
【R06PM1問3】 SELECT 組織コード,A.従業員コード,COALESCE(SUM(計画時間),0)AS 計画時間合計, NTILE(3) OVER (PARTITION BY 【ア;組織コード】 ORDER BY 【イ;COALESCE(SUM(計画時間),0)】) AS 時間階級, RANK() OVER ( ORDER BY 【イ;計画時間】 ) AS 時間ランク FROM 【ウ;従業員】 A LEFT OUTER JOIN 【エ;稼働計画】 B ON A.従業員コード=B.従業員コード AND 計画年=’2024’ AND 計画月=’11’ WHERE 役職コード=’SE’ GROUP BY 組織コード,A.従業員コード ORDER BY 組織コード,時間ランク,A.従業員コード
例えば AVG() や ORDER BY でも、NULLをそのままにしておくと扱いにくい(ソート順が最後・除外される等)ため、0に変換しておくのが実務的です。
R05問3
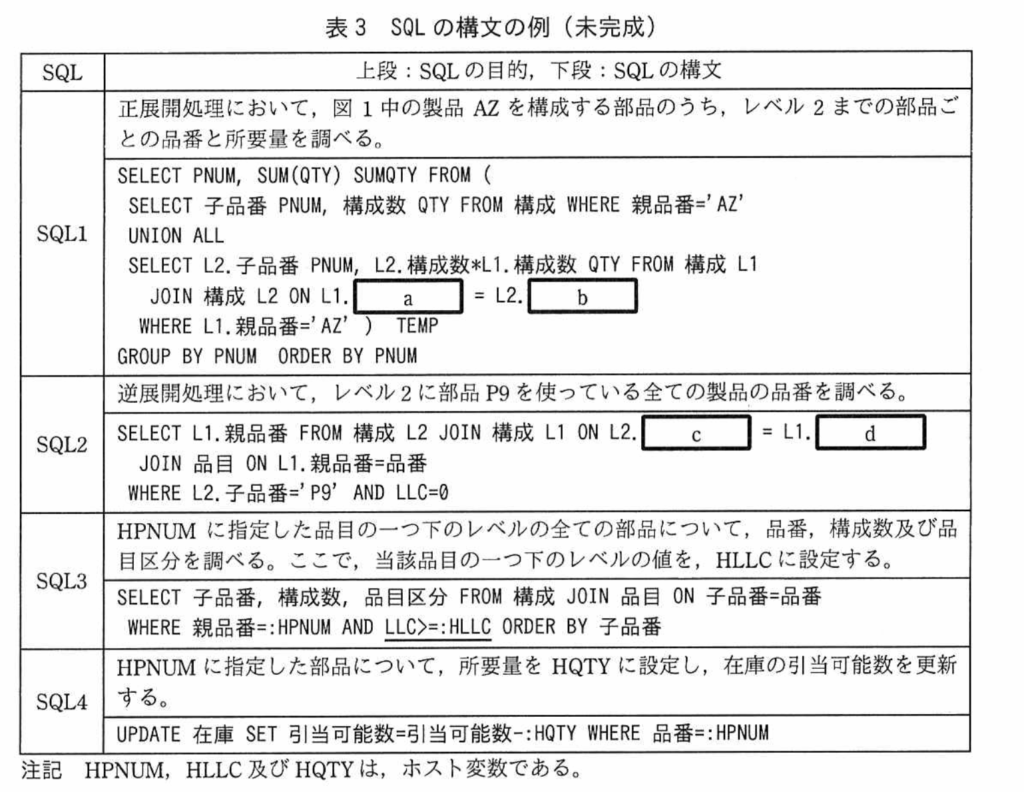
【R05PM1問3】表3 圃場ごと、農事日付ごとに1日の平均温度と行数を調べるSQL。 <SQL1> WITH R ( 圃場ID、農事日付、日平均温度、行数) AS( SELECT 【a;圃場ID、農事日付、AVG(分平均温度)】、COUNT(*) FROM 観測 GROUP BY 【b;圃場ID、農事日付】) SELECT * FROM R
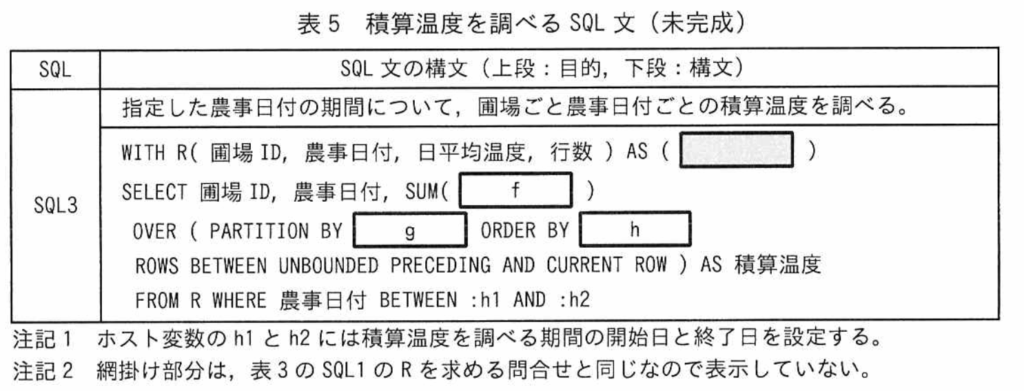
【R05PM1問3】表5 指定した農事日付の期間について、圃場ごと農事日付ごとの積算温度を調べるSQL。 WITH R ( 圃場ID、農事日付、日平均温度、行数 ) AS ([非表示]) SELECT 圃場ID、農事日付、SUM(【f;日平均温度】) OVER ( PARTITION BY 【g;圃場ID】 ORDER BY 【h;圃場ID、農事日付】 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS 積算温度 FROM R WHERE 農事日付 BETWEEN :h1 AND :h2
文
処理内容
ポイント・解説
WITH R (圃場ID, 農事日付, 日平均温度, 行数) AS (...)
事前に作成したCTE R を参照
前問で作成した「圃場ごと・日ごとの日平均温度・行数」を格納した仮テーブル
SELECT 圃場ID, 農事日付, SUM(日平均温度) OVER (...) AS 積算温度
積算温度(累積温度)を計算
ウィンドウ関数 SUM() OVER() を使用。累積計算することで、指定期間内の積算温度を求める
PARTITION BY 圃場ID
圃場ごとに累積計算を区切る
圃場ごとに別々に累積するため、他圃場のデータは混ざらない
ORDER BY 圃場ID, 農事日付
農事日付順に累積
日付順に積算されることで、「今日までの累計温度」を取得
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
現在行までの全行を対象
「その日の前日まで+当日」を範囲として累積計算する
FROM R WHERE 農事日付 BETWEEN :h1 AND :h2
指定期間のデータのみ抽出
不要な日付データは対象外にして、効率的に集計
ポイント
💡 SQLのWITH句(共通テーブル式)の処理フロー
ステップ
SQLの記述要素
処理内容
役割とブログ向け解説ポイント
ステップ 1
WITH R (列名...) AS (
仮想テーブル(CTE)を**R**と命名し、最終的な列名(例:日平均温度)を定義します。
【設計図の作成】 複雑な計算結果に分かりやすい名前をつけ、メインクエリでの利用に備えます。
ステップ 2
FROM 観測
データの元となる**「観測」テーブル**を指定します。
【データの取得元】 どのテーブルのデータを使うかを定義します。
ステップ 3
GROUP BY 圃場ID, 農事日付
観測データを、指定されたキー(圃場IDと農事日付)の単位でグループ化します。
【集計単位の決定】 この単位(例:「圃場Aの10月1日」)で後の計算が実行されます。
ステップ 4
SELECT ... AVG(分平均温度), COUNT(*)
GROUP BYで区切られた各グループに対して、集計関数(AVG、COUNT)を実行し、計算結果を仮想テーブル R の列に割り当ててデータを作成します。
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
フレームの範囲を、パーティションの**最初から最後までの「全行」**に設定します。
R04問2
【R04PM1問2】図2 SELECT A.モデル名 AS 新モデル名、C.モデル名 AS 旧モデル名、A.定価 AS 新定価、C.定価 AS 旧定価 FROM 見積回答明細 A INNER JOIN 見積回答 B ON A.見積依頼番号=B.見積依頼番号 INNER JOIN 商品 C ON A.【a;商品コード】 = C.【a;商品コード】 WHERE B.見積回答日 > C.更新日 AND (A.モデル名 <> C.モデル名 【b;OR】 A.定価 <> C.定価
・【a;】には、商品テーブルと見積回答明細テーブルの結合条件の列名が入る。両テーブルに共通している、’商品コード’が入る。 ・INNNER JOINを使う理由は、見積時点で、モデル名、定価を更新したものだけ、更新すれば良いので、 LEFT OUTER JOINでは、すべての「見積回答明細」が含まれ、見積回答に使われていない「商品」は含まれない。(そのような場合は滅多にないと思うので、どちらでも良いと思うが) RIGHT OUTER JOINでは、すべての「商品」が含まれ、見積回答に使われていない商品すべてを含み、冗長になる。(見積しない商品など、通常は考えにくいので、これでも良いと思う。)
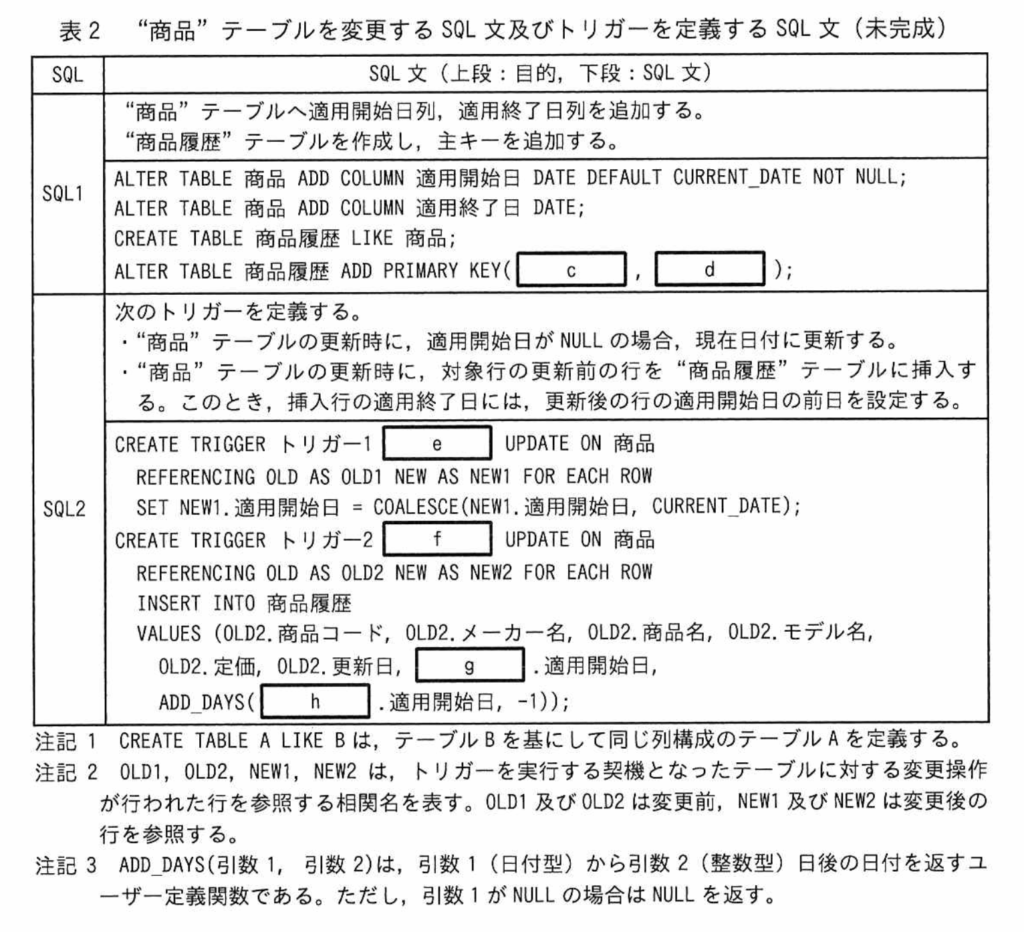
【R04PM1問2】表2 <SQL1> ALTER TABLE 商品 ADD COLUMN 適用開始日 DATE DEFAULT CURRENT_DATE NOT NULL; ALTER TABLE 商品 ADD COLUMN 適用終了日 DATE; CREATE TABLE 商品履歴 LIKE 商品; ALTER TABLE 商品履歴 ADD PRIMARY KEY (【c;商品コード】、【d;適用開始日】);
サブタイプ貸した場合の主キーの選定の問題。スーパータイプの主キーに倣って設定する。
<SQL2> CREATE TRIGGER トリガー1 【e;BEFORE】 UPDATE ON 商品 REFERENCING OLD AS OLD1 NEW AS NEW1 FOR EACH ROW SET NEW1.適用開始日=COALESCE(NEW1.適用開始日、CURRENT_DATE); CREATE TRIGGER トリガー2 【f;AFTER】 UPDATE ON 商品 REFERENCING OLD AS OLD2 NEW AS NEW2 FOR EACH ROW INSERT INTO 商品履歴 VALUES(OLD2.商品コード、OLD2.メーカー名、OLD2.商品名、OLD2.モデル名、OLD2.定価、OLD2.更新日、【g;OLD2】.適用開始日、ADD_DAYS(【h;NEW2】.適用開始日、-1));
【R04PM1問3】表4 WITH TEMP (出庫番号、ピッカーID、棚番号、商品コード、出庫時刻、出庫間隔時間) AS (SELECT A.出庫番号、A.ピッカーID、B.棚番号、B.商品コード、B.出庫時刻、B.出庫時刻 – COALESCE( LAG(B.出庫時刻) OVER ( PARTITION BY 【x;】 ORDER BY B.出庫時刻)、A.出庫開始時刻 )AS 出庫間隔時間 FROM 出庫 A JOIN 出庫指示 B ON A.出庫番号=B.出庫番号 AND 出庫日ーCAST( :h AS DATE) ) GROUP BY 棚番号、商品コード ORDER BY 出庫間隔時間合計 DESC 【x】に入れる値 【あ】;棚の前での待ち時間を含むが、商品の梱包及び出荷担当者への受け渡しにかかった時間も含まれる。→『A.ピッカーID』 <解説> ピッカーID単位での区分けとなり、ピッカーIDごとの業務の開始〜終了の時間で計測する。 よって、「出庫番号割当て→ピッカー移動→棚での商品ピッキング→担当者への受渡し・梱包→終了後、次の出庫番号の割当て〜以降順次」のように、ピッカーIDに紐づく棚番号ごと、商品ごとの時間で合計される。
LAG(B.出庫時刻) OVER (PARTITION BY 【x】 ORDER BY B.出庫時刻)
前回の出庫時刻を取得
【x】で指定した単位(ピッカー・棚・出庫番号)ごとに直前の出庫時刻を参照
COALESCE(…, A.出庫開始時刻)
NULL時は出庫開始時刻を代入
最初の出庫(LAGがNULLになる場合)に対応
出庫時刻 - COALESCE(…)
出庫間隔時間を算出
現在の出庫と直前の出庫の時間差を計算
R03問3
【R03問3】表3 WITH TEMP (TOTAL) AS (SELECT COUNT(*) FROM 物件) SELECT 沿線、FLOOR 【ハ;COUNT (*)】 * 100 / 【二;TOTAL】) FROM 物件 CROSS JOIN TEMP WHERE エアコン=’1’ AND オートロック=’1’ GROUP BY 【ホ;沿線、TOTAL】
【ハ;COUNT (*)】は、WHERE句での条件でのカウント。 WITH TEMPのTOTALは、物件テーブルでの総数のカウントという違いがある。
【R03問3】表4 INSERT INTO 物件設備 ( 物件コード、設備コード、設備済個数 ) SELECT 【a;物件コード、’A1’、1】 FROM 物件 WHERE 【b;エアコン=’Y’】 【c;UNION】 SELECT 【d;物件コード、’A2’、1】 FROM 物件 WHERE 【e;オートロック=’Y’】
処理手順
SQL文の流れ
処理内容のイメージ
①
SELECT 物件コード, 'A1', 1 FROM 物件 WHERE エアコン='Y'
エアコン付き物件の一覧を作成
②
UNION SELECT 物件コード, 'A2', 1 FROM 物件 WHERE オートロック='Y'
オートロック付き物件を追加し、重複を除去
③
INSERT INTO 物件設備 (...)
上記の結果を物件設備テーブルに一括登録
構文
役割・機能
この問題での使われ方
ポイント・注意点
INSERT INTO
既存テーブルに新しい行を追加する
物件設備 テーブルに、条件に合う設備情報(物件コード+設備コード+設備済個数)を追加している
データ登録用。VALUESの代わりにSELECT句の結果を挿入している点が特徴。
SELECT
テーブルからデータを取得する
物件 テーブルから、エアコン='Y'やオートロック='Y'の行を選択
SELECTの結果を直接INSERTに流し込む構成。抽出条件により異なる設備を判定。
WHERE
行を絞り込む
WHERE エアコン='Y' や WHERE オートロック='Y'
条件に合う物件のみを対象。ブール条件で分岐処理を実現。
UNION
複数のSELECT結果を1つに結合(重複行は削除)
エアコンのSELECT結果と、オートロックのSELECT結果を結合
複数設備を一括で登録できるようにしている。重複行を許す場合はUNION ALL。
VALUES
直接値を指定して挿入する
今回は使用していない
小規模挿入では使うが、今回はSELECT結果を使うため不要。
FROM
参照元テーブルを指定
FROM 物件
今回は1つのテーブルのみ参照。JOIN不要。
テーブル別名
テーブル名を短くして可読性を上げる
今回は明示的に使用していない(例:物件 AS Pなども可)
複数テーブルをJOINする場合は必須。単一テーブルでは省略可。
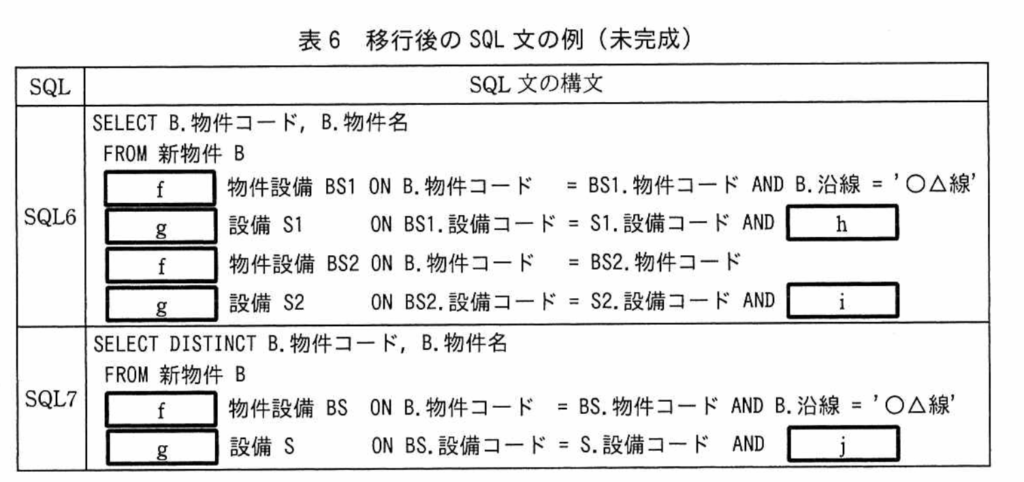
【R03問3】表6 <SQL6> SELECT B.物件コード、B.物件名 FROM 新物件 B 【f;INNER JOIN】物件設備 BS1 ON B.物件コード = BS1.物件コード AND B.沿線 = ’○△線’ 【g;INNER JOIN】設備 S1 ON BS1.設備コード = S1.設備コード AND 【h;S1.設備コード=’A1’】 【f;INNER JOIN】物件設備 BS2 ON B.物件コード = BS2.物件コード 【g;INNER JOIN】設備 S2 ON BS2.設備コード = S2.設備コード AND 【i;S2.設備コード=’A2’】
<SQL7> SELECT DISTINCT B.物件コード、B.物件名 FROM 新物件 B 【f;INNER JOIN】物件設備 BS ON B.物件コード = BS.物件コード AND B.沿線 = ’○△線’ 【g;INNER JOIN】設備 S ON BS.設備コード = S.設備コード AND 【j;BS.設備コード=’A1’ OR BS.設備コード=’A2’】
区分
構文・句
役割・機能
SQL6での使われ方
SQL7での使われ方
補足ポイント
【f】
INNER JOIN(内部結合)
両方のテーブルに存在するデータだけを取得
新物件Bと物件設備BS1・BS2を、物件コードで結合している
同様に、新物件Bと物件設備BSを結合
結合条件を満たすデータのみ対象。設備を持たない物件は除外される。
【g】
INNER JOIN(続き)
結合した設備テーブルの内容を取り込む
設備S1, S2をそれぞれ結合して設備情報を取得
設備Sを結合して設備コードを参照
設備名やコードなど、マスタ的情報を参照するために使用。
【h】【i】
設備コードの条件指定
特定の設備コードを持つ行を選択
S1.設備コード='A1'(エアコン)S2.設備コード='A2'(オートロック)
—(まとめてORで指定)
SQL6では設備ごとにテーブルを分け、両方の条件を満たす物件を抽出。
【j】
OR条件(複数指定)
複数の設備を1つのテーブル結合で判定
—
BS.設備コード='A1' OR BS.設備コード='A2'
SQL7では1回の結合で複数設備をまとめて判定。
DISTINCT
重複排除
同じ物件が複数設備で重複して出ないようにする
—
使用している(重複防止)
OR条件では重複しやすいので必須。
結合数
—
—
設備テーブル×2(S1, S2)
設備テーブル×1
SQL6は厳密一致(両方あり)/SQL7はゆるい一致(どちらかあり)。
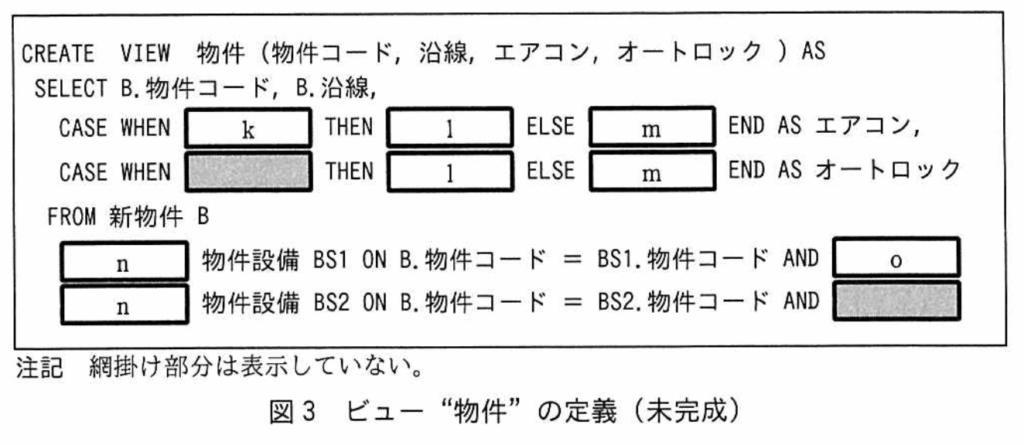
【R03問3】図3 CREATE VIEW 物件 (物件コード、沿線、エアコンmオートロック) AS SELECT B.物件コード、B.沿線 CASE WHEN 【k;BS1.設備コード】 THEN 【l;’Y’】 ELSE 【m;’N’】 END AS エアコン、 CASE WHEN 【非表示】 THEN 【l;’Y’】 ELSE 【m;’N’】 END AS オートロック FROM 新物件 B 【n;LEFT OUTER JOIN】 物件設備 BS1 ON B.物件コード = BS1.物件コード AND 【o;BS1.設備コード=’A1’】 【n;LEFT OUTER JOIN】 物件設備 BS2 ON B.物件コード = BS2.物件コード AND 【非表示】














コメント