
ここでは、データベーススペシャリスト試験の対策として、『性能と索引設計』についての問題を扱った過去問の解説を紹介します。対象は、平成16年度午後1問4の問題となります。
設問1
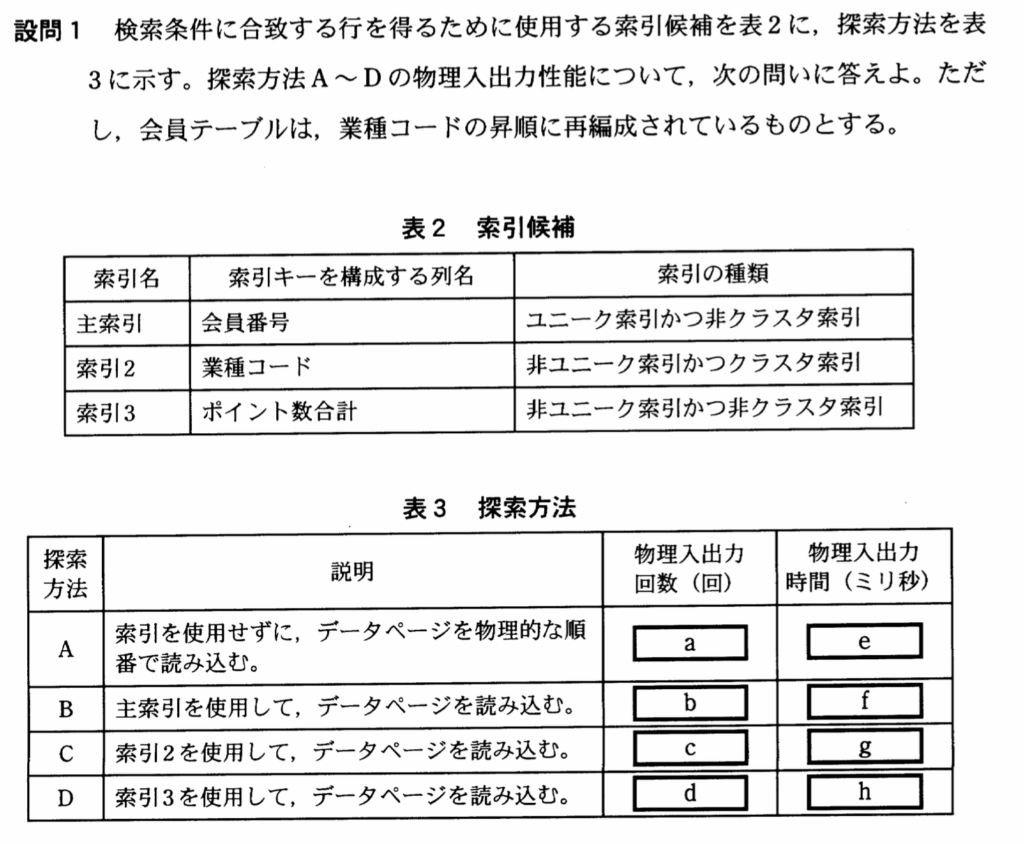
設問1(1)


設問1(1)は、探索方法A~Dについて、検索条件に合致する行が最少数のデータページに収まっている場合のデータページの物理入出力回数を求める問題。表3の【a】〜【d】を埋める。

【a】
「A;索引を使用せずにデータページを物理的な順番で読み込む」とあるので、全ページを順番に読み込むこととなる。よって、全ページ数が答えとなり、〔検索処理の内容〕の「(1)会員テーブルの主な仕様」の②から、『400,000』回となる。


【b】
「B;主索引を使用して、データページを読み込む」時の物理入出力回数を求める問題。
「主索引を使用して」とあり、表2から「主索引の索引の種類」は、「ユニーク索引かつ非クラスタ索引」であることが分かる。
〔検索処理の内容〕の「(2)検索処理実行時の前提条件」⑥「非クラスタ索引を使用したデータページの読込みは、どの非クラスタ索引の場合も同程度にランダムに行われる。その検索処理中にすでに読み込んだデータページを再度読み込むときでも、必ず物理入出力が発生する」とある。つまり、「ランダム読込み」なので、行数分のページ読み込みが発生し、「再読み込みでも、物理入出力が発生する」ので、『読み込む行数=データページ数』となる。
「(1)会員テーブルの主な仕様」の①「行数は、10,000,000行」とあるので、『10,000,000』回となる。


【c】
・「C;索引2を使用してデータページを読み込む」
・索引2;(列名);業種コード、(索引の種類);非ユニーク索引かつクラスタ索引
”業種コード”による索引は、表1「WHERE句述語による絞込み率」から「絞込み率;5%」と分かる。
〔検索処理の内容〕の「(2)検索処理実行時の前提条件」⑤「クラスタ索引を使用したデータページの読込みは、物理的な順番で行われる」とあるので、『全ページ数×5%』が物理入出力数となる。
したがって、(全ページ数;400,000)×(絞込み率;5%)=『20,000』回となる。
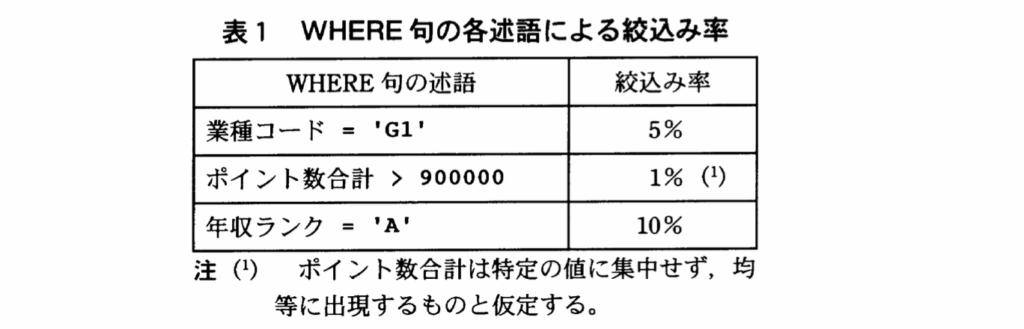
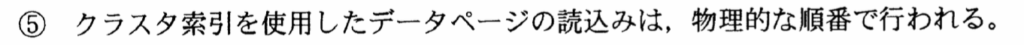
【d】
・「D;索引3を使用してデータページを読み込む」
・索引3;(列名);ポイント数合計、(索引の種類);非ユニーク索引かつ非クラスタ索引
・”ポイント数合計”の絞込み率;1%(表1「WHERE句述語による絞込み率」から)
〔検索処理の内容〕の「(2)検索処理実行時の前提条件」⑥「非クラスタ索引を使用したデータページの読込みは、どの非クラスタ索引の場合も同程度にランダムに行われる。その検索処理中にすでに読み込んだデータページを再度読み込むときでも、必ず物理入出力が発生する」とある。つまり、「ランダム読込み」なので、行数分のページ読み込みが発生し、「再読み込みでも、物理入出力が発生する」ので、『読み込む行数=データページ数』となる。
よって、(全行数;10,000,000)×(絞込み率;1%)=『100,000』回となる。
ポイント
・クラスタ索引(順次アクセス);データページ数分の物理入出力発生
・非クラスタ索引(ランダムアクセス);行数分の物理入出力発生
設問1(2)

設問1(2);物理入出力時間(ミリ秒)を求める問題。
回答方式;表3【e】〜【h】に適切な計算式を入れる
対象;探索方法A~D
条件;・それぞれのデータページの物理入出力回数をN回とする。
・データページをランダムに読み込むのに要する物理入出力時間をTミリ秒とする。
・データページを外部記憶装置から物理的な順番で読み込む場合、1ページあたりの物理入出力時間は、ランダムに読み込む場合の10分1(検索処理の内容〕の「(2)検索処理実行時の前提条件」⑧より)
【e】
「A;索引を使用せずにデータページを物理的な順番で読み込む」
物理的な順番で読み込むので、Tミリ秒の1/10となり、
物理入出力時間は、(物理入出力回数;N)×(物理入出力時間;1/10T)により計算できる。
したがって、『NT/10』となる。
【f】
「B;主索引を使用して、データページを読み込む」
〔検索処理の内容〕の「(2)検索処理実行時の前提条件」⑥「非クラスタ索引を使用したデータページの読込みは、どの非クラスタ索引の場合も同程度にランダムに行われる。」とある。
物理入出力時間は、(物理入出力回数;N)×(物理入出力時間;T)により計算できる。
したがって、『NT』となる。
【g】
・「C;索引2を使用してデータページを読み込む」
・索引2;(列名);業種コード、(索引の種類);非ユニーク索引かつクラスタ索引
〔検索処理の内容〕の「(2)検索処理実行時の前提条件」⑤「クラスタ索引を使用したデータページの読込みは、物理的な順番で行われる」とあるので、順次アクセスである。
物理的な順番で読み込むので、Tミリ秒の1/10となり、
物理入出力時間は、(物理入出力回数;N)×(物理入出力時間;1/10T)により計算できる。
したがって、『NT/10』となる。
【h】・「D;索引3を使用してデータページを読み込む」
・索引3;(列名);ポイント数合計、(索引の種類);非ユニーク索引かつ非クラスタ索引
〔検索処理の内容〕の「(2)検索処理実行時の前提条件」⑥「非クラスタ索引を使用したデータページの読込みは、どの非クラスタ索引の場合も同程度にランダムに行われる。」とある。
物理入出力時間は、(物理入出力回数;N)×(物理入出力時間;T)により計算できる。
したがって、『NT』となる。
ポイント
・クラスタ索引(順次アクセス);物理入出力時間短い
・非クラスタ索引(ランダムアクセス);物理入出力時間長い

設問2

設問2は、連結索引に関する問題である。索引リーフページを読み込む物理入出力性能について、検索条件に合致する索引キーが最少数の索引リーフページに収まっている場合の、索引リーフページの物理入出力回数を求める。
<前提>
・データページを読み込むのに要する物理入出力時間はどの複合列索引を使用しても同じ
・会員テーブルは、会員番号昇順に再編成済み
・表4「複合列索引候補」
・表5「複合列索引による探索方法」
<回答方式>
・表5中の【i】【j】に入れる数値を答える
<前提知識>
[連結索引とは]
・ソートの順番は、左から。
・2列の場合、第1列によるソート→第1列に等しいもの同士が第2列にソート
・選択性(=絞り込み効果)が高い列(=値の種類が多く、絞れる度合いが大きい)を先頭に置く
【i】
・「E;索引4を使用して、データページを読み込む」
・[索引4]
(索引キー);ポイント数合計、業種コード
(索引の種類);非ユーク索引かつ非クラスタ索引
索引4は、ポイント数合計によりソートし、同じポイント数合計同士で、業種コードをソートする。
ここで、ポイント数合計の仕様を確認すると、〔検索処理の内容〕の「(2)検索処理実行時の前提条件」⑧「ポイント数合計は、〜中略〜 0〜99,999,999の整数である」とある。つまり、100,000,000通り存在する。〔検索処理の内容〕の「(1)会員テーブルの主な仕様」の①「行数は、10,000,000行」であり、ポイント数合計の方が多く、ポイント数合計が同じものが存在している数は少ないと考えられる。
よって、同じポイント数合計のものが存在していないと仮定すると、第2列のソート(同じポイント数合計同士での業種コードのソート)は起こらないので、『ポイント数合計の行数が索引リーフページの物理入出力回数』になる。なお、表1「WHERE句述語による絞込み率」から、『絞込み率;1%』と分かる。
ここで、〔検索処理の内容〕の「(1)会員テーブルの主な仕様」の③「索引リーフページ数は、すべて50,000ページ」とあるので、『索引データページ数;50,000』と分かる。
したがって、(索引データページ数;50,000)×(絞込み率;1%)=『500』回となる。
【j】
・「F;索引5を使用して、データページを読み込む」
・[索引5]
(索引キー);業種コード、ポイント数合計
(索引の種類);非ユーク索引かつ非クラスタ索引
索引5は、業種コードによりソートし、同じ業種コード同士で、ポイント数合計をソートする。
業種コードは、ポイント数合計のように特記事項の記載はない。よって、連結索引処理が通常通り実行可能であると考え、『①業種コードでのソート→②同じ業種コードでポイント数合計をソート』を考える。つまり、『業種コードで絞り込んだ上で、ポイント数合計で絞り込める』。
表1「WHERE句述語による絞込み率」から、それぞれの絞込み率は、『業種コード;5%』、『ポイント数合計;1%』と分かる。
ここで、〔検索処理の内容〕の「(1)会員テーブルの主な仕様」の③「索引リーフページ数は、すべて50,000ページ」とあるので、『索引データページ数;50,000』と分かる。
したがって、(索引データページ数;50,000)×(業種コード;5%)×(ポイント数合計;1%)=『25』回となる。
ポイント
索引リーフページ:索引の一番下の階層。実際のデータ行(または行ポインタ)への参照が並んでいる。
最少数に収まっている場合:検索対象のキー値ができるだけ連続して存在するため、必要なリーフページ数が最小限になるケース。
・連結索引とは、索引キー順によるソート。
連結索引が2列の場合、①第1列でのソート→②同じ第1列同士でソート。
・処理速度向上(入出力回数低減)のためには、先頭に持ってくるべき列」は、選択性(=区別できる力)が高い列に設定する。
・今回の場合、第1列がほぼユニークだと、第2列以降は事実上活かせない。
『①ポイント数合計での絞込み(1%)→②ポイント数合計が同じものがない→③業種コードでの絞込みを活かせない→<結論>ポイント数合計のみでの絞込み(1%)』

設問3



設問3は、クラスタ索引に指定する列を選択する際のトレードオフと検索性能の最適化に関する理解を問うものです。
索引5、6を検討し、索引6をクラスタ索引を採用とした理由を2つ答える問題となる。
<前提条件>
・検索処理内容;会員テーブルから、業種コード;G1、年収ランク;A、ポイント数合計;90万点超えを地域コード順に出力
・表6「クラスタ索引候補」
・[索引5](索引キー);業種コード、ポイント数合計
・[索引6](索引キー);業種コード、地域コード
・表5「検索に使用するSQL文」;ORDER BY 地域コード
・[絞込み率]業種コード;5%、ポイント数合計;1%
<回答方式>
・索引6の長所2つを記述
処理向上の基本は、『テーブル行順と索引順の一致』である。
今回の索引6の場合、クラスタ索引により、索引順で検索する。索引キーの設計について確認していく。
検索処理内容にあるように、”地域コード”順に出力する。〔検索処理内容〕⑩「会員テーブルは、クラスタ索引の索引キー列順に物理的に並ぶように、定期的に再編成される」とあるので、テーブルは索引6の索引キー{業種コード、地域コード}順に並んでいる。
したがって、1つ目は『テーブルの行順と索引の行順が一致しているので、処理が早い』(これは索引5でも一緒??)
次は、「再編成による処理時間」に注目した時のメリットについて考える。
〔検索処理内容〕⑩「会員テーブルは、クラスタ索引の索引キー列順に物理的に並ぶように、定期的に再編成される」とあるので、索引キー順に定期的に更新されることになる。2つ目の回答は、この『再編成による更新の頻度(多いか、少ないか)による時間』に関してであり、『更新頻度が多いとその分、処理時間がかかる』。再編成による更新でテーブル順が変更される可能性がある。索引5の”ポイント数合計”の場合、ポイントの加算、減算等により変更されると考えられる。一方、索引6の”地域コード”は変更される可能性は低いと考えられる。つまり、索引5では、更新によりテーブル順が変わり処理が発生するが、索引6では再編成による更新は索引5よりは少ない。
したがって、『再編成によるテーブル構造の更新処理の時間が索引6の方が少なく、処理時間が短くなるから』となる。(再編成のみの処理時間に着目した回答。テーブル順と索引順は担保される)
3つ目は、『SQL文との相性』に着目した回答である。
SQL文の述語には、「ORDER BY 地域コード」とある。ORDER BY句の場合、メモリーソートかディスクソートが発生する。しかし、その前にインデックスによるソートが行われる。つまり、①インデックスによるソート→②ORDER BY句でのソート(メモリーorディスク)という処理の流れになる。
<索引5の場合>
①”業種コード”、”ポイント数合計”によるソート
→②ORDER BY句(”地域コード”)によるソート
<索引6の場合>
①”業種コード”、”地域コード”によるソート
→②ORDER BY句(”地域コード”)によるソートは不要
となり、索引6の①と②で同じ列値になるので、ソート処理は行われず、この分の処理時間がなくなる。
したがって。『ORDERBY句の”地域コード”の順で物理的に読み込めるので、改めてソートする必要がないから』、『索引キーとORDER BY句の”地域コード”が一致しているので、ORDER BY句でのソートは行われず、その分処理時間を短縮できるから』となる。
4つ目は、『インデックス』に着目した回答である。
インデックスは検索処理向上に効果があるが、更新処理の発生がある。
この『更新処理発生の頻度の差』により処理性能で差が出る。
<索引5の場合>
”ポイント数合計”の値の変更が多いと考えられる。よって処理時間は長い。
<索引6の場合>
”地域コード”の値の更新は稀であると考えられる。よって、処理時間は短い。
したがって、『インデックスの更新処理が索引6の方が少ないため、その分処理時間が短くなるから』となる。
<ポイント>
・索引キーの値の順番(クラスタ索引)と行の順番が一致しているので、処理が早い【クラスタ索引VS非クラスタ索引】
・再編成の頻度が少ない(クラスタ索引と行の順番の一致)ので、処理が早い【再編成の処理頻度の違いによる処理時間差}
・ORDER BY句の列値の順番で読み込めるので、検索性能がよく、処理が早い【ORDER BY句での処理不要】
・索引が更新されないことで、インデックス更新が不要となり、処理が早い【インデックス更新時間の違い】
(補足ポイント)
・ORDER BY句;メモリーソートかディスクソートが発生。
・メモリーソート;メモリーでのソート?
・ディスクソート;ディスクでのソート?
・ソートの処理フローは??
・インデックスの長所;検索処理性能の向上
・インデックスの短所;更新処理により性能低下(データ更新によりインデックス更新も必要)
<まとめ>
◾️処理向上のための確認ポイント
・テーブルの並び順と索引の並び順が一致しているか?
→①クラスタ索引にし、ランダムアクセスを回避
・索引キーは、値の更新が少ないものにしたか?
→①再編成処理を少なくし、処理時間を減らせる
②インデックス更新処理を減らせる
・索引キーと検索SQL文のORDER BY句が一致しているか?
→①ORDER BY句によるソートを不要にできる
◾️クラスタ索引設計ポイント
□値の更新頻度;再編成処理とインデックス更新処理に影響
→値の更新が少ない列を索引キーにする
・少ない;「地域コード」のような静的なデータをクラスタ索引にすることで、この再編成・維持管理コストを最小限に抑えられます。
・多い;「ポイント数合計」のような変動性の高いデータをクラスタ索引にすると、データの更新のたびに大きなオーバーヘッドが発生します。
💡 クラスタ索引設計のための3つの最重要確認ポイント
クラスタ索引はテーブルの物理的なデータ配置を決定するため、そのキー選定はデータベースの検索性能と更新処理性能(維持管理コスト)に最も大きな影響を与えます。
| 確認ポイント | 目的とする効果 | 索引キー選定の具体例 |
|---|---|---|
| 1. 索引キーは「静的」な列か? | 更新コストの最小化:索引キーの更新による重い物理的なデータ移動(再編成)と、他の索引の連鎖的な更新を回避する。 | 〇 地域コード、性別、登録日など(変更されない、または稀にしか変更されない列) |
| 2. ORDER BY句の列が含まれているか? | 検索性能の極大化:SQLのORDER BY句と索引キー順を一致させ、重いソート処理(ディスクソート)を不要にする。 | ORDER BY句の列(この問題では地域コード)を、複合索引のキーに含める。 |
| 3. テーブルの並び順(クラスタ索引)を利用しているか? | ランダムアクセスの回避:クラスタ索引により、データを順次アクセス(シーケンシャル)で読み込めるようにし、I/O時間を大幅に短縮する。 | 索引を使用しない全件走査(Full Scan)や、範囲検索の性能を向上させる。 |
データベース性能設計の要点:クラスタ索引の適正検討
情報処理技術者試験(DBスペシャリスト)で頻出の、クラスタ索引のキー選定における重要な検討ポイントをまとめます。
◾️ 理由1:検索性能の極大化(ORDER BY句の回避)
- 最優先事項:ORDER BY句の回避
SQL文のORDER BY句で指定される列をクラスタ索引のキー(複合キーの一部でも可)に含めることで、検索結果を物理的にその順番で取得できます。これにより、メモリ上やディスク上でのソート処理(重い処理)を完全に省略できます。
◾️ 理由2:更新処理の負荷低減(維持管理コストの最小化)
- クラスタ索引キーは「静的」な列を選ぶ
クラスタ索引のキーが更新されると、そのデータ行は物理的な並び順を維持するためにディスク上の別の場所へ移動(再編成)する必要があります。キーの更新頻度が高い(例:ポイント数合計)と、この重い維持管理コストが頻繁に発生します。 - そのため、更新頻度が低い列(例:地域コード、性別など)をクラスタ索引キーに採用することで、更新処理全体の性能低下を防ぎます。
◾️ 結論:クラスタ索引の選定基準
クラスタ索引はテーブルにつき一つしか設定できません。選定時には、以下のトレードオフを考慮しましょう。
- 更新頻度: 極力、値の変更がない静的な列を選ぶ。
- 検索処理: 頻度の高い検索処理における、ORDER BY句やGROUP BY句の列と一致させることを優先する。


