
ここでは、データベーススペシャリスト試験の対策として、『SQL処理時間』についての問題を扱った過去問の解説を紹介します。対象は、令和3年度午後1問2の問題となります。
出題趣旨
・処理時間の見積もり
・バッファプールのチューニング
・区分表の設計
・ロギングの性能に関する考慮点
【設問1】参照処理の処理時間の見積もり
【設問2】区分化に関する設問
【設問3】ログに関する設問
設問1ー(1)
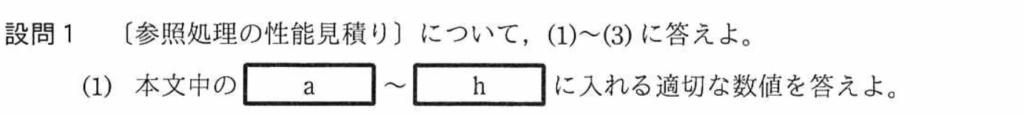
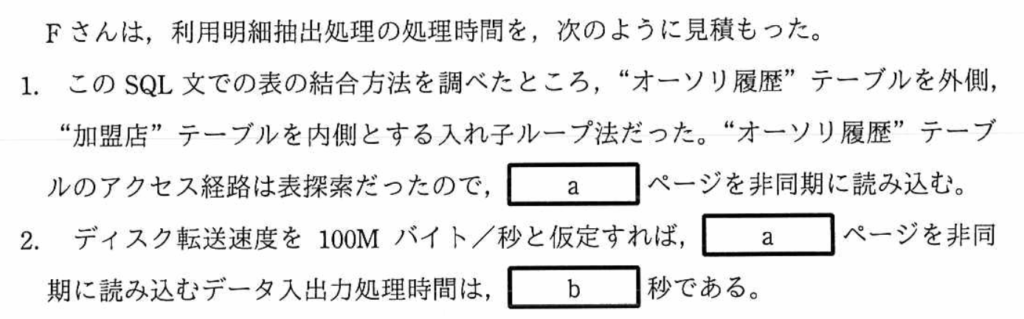
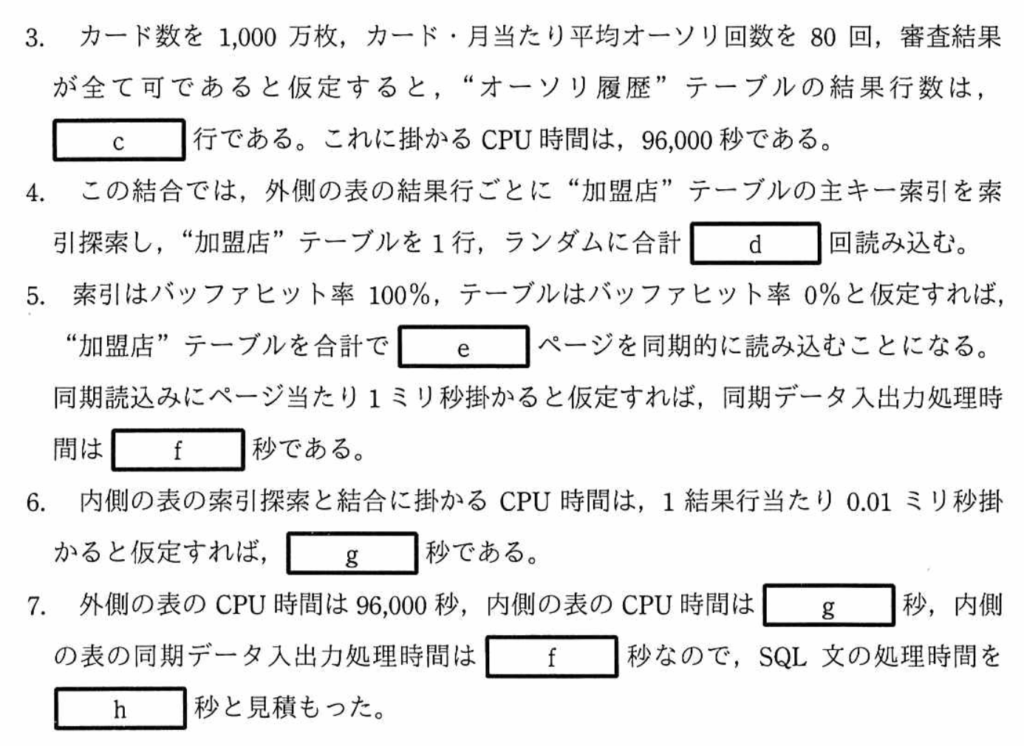
表1の容量見積もりを確認しながら回答していく。

空欄(a)
「”オーソリ履歴”テーブルのアクセス経路は表探索」という記載があるので、全行を読み込むことになる。
表1から”オーソリ履歴”テーブルのページ数は「24億」とあり、空欄(a)は『2,400,000,000』となる。
空欄(b)
24億ページを非同期で読み込む時の処理時間を求める。
〔RDBMSの主な仕様〕の「2.データ入出力とログ出力」の(2)から、「データ入出力とログ出力は4,000バイトのページ単位に行われる」と記載がある。よって、入出力するデータの容量は、次のように計算できる。
4,000[バイト]×2,400,000,000[ページ]=9,600,000,000[バイト]=9,600,000M[バイト]
「ディスク転送速度を100Mバイト/秒」と記載があるので、
9,600,000M[バイト]/100M[バイト/秒]=96,000[秒]
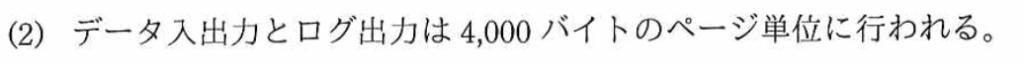
空欄(c)
”オーソリ履歴”テーブルの結果行が入る。
「カード数を1,000万枚、カード・月当たり平均オーソリ回数を80回、審査結果が全て可であると仮定」と記載があるので、
80[回/月]×10,000,000[枚]=800,000,000[行]
空欄(d)
”加盟店”テーブルを読み込む回数が入る。
「外側の表の結果行ごとに”加盟店”テーブルの主キー索引を索引探索し、”加盟店”テーブルを1行、ランダムに」と記載がある。「外側の表」は、”オーソリ履歴”テーブルのことなので、”オーソリ履歴”テーブルの行数(=800,000,000行)を読み込む。
空欄(e)
”加盟店”テーブルの読み込むページ数を考える。
「索引はバッファヒット率100%、テーブルはバッファヒット率0%と仮定」と記載があるので、800,000,000回の全ての回で、一ページを同期的に読み込むので、800,000,000ページ読み込むことになる。
空欄(f)
同期データ入出力処理時間を求める問題である。
ページあたり1ミリ秒かかるので、
800,000,000[ページ]×1m[秒]=800,000秒
空欄(g)
内側の表の索引と結合に掛かるCPU時間を求める問題。
ここで、内側の表とは、”加盟店”テーブルである。空欄(d)で求めたように、”加盟店”テーブルでの読み込む回数=行数となっている。
1結果行あたり、0.01m秒掛かるとすると、
800,000,000[行]×0.01m[秒]=8,000[秒]
空欄(h)
SQL文の処理時間を求める問題。
SQL文の処理時間=CPU処理時間(外側)+CPU処理時間(内側)+同期データ入出力時間(内側)
=96,000[秒]+8,000[秒]+800,000[秒]
=904,000[秒]
SQL処理時間については、〔RDBMSの主な仕様〕にも記載がある。

【”オーソリ履歴”テーブル(外側の表)】
同期方法:非同期
①CPU処理時間:96,000[秒]
②データ入出力処理時間:96,000[秒]
このうち、大き方が、SQL処理時間となるので、『96,000[秒]』

【”加盟店”テーブル(内側の表)】
同期方法:同期
①CPU処理時間:8,000[秒]
②データ入出力処理時間:800,000[秒]
SQL処理時間は、「①CPU処理時間」と「②データ入出力処理時間」の合計となるので、
『808,000[秒]』。
設問1ー(2)

見積もったSQL処理時間が長いので、短縮案の検討を行う。

【”加盟店”テーブル】
現状方針:索引はバッファヒット率100%、テーブルはバッファヒット率0%
現状処理:ランダムに読み込む回数分だけ入出力が発生
改善方針:”加盟店”テーブルのデータバッファを増やし、バッファヒット率を100%にする。
改善処理:一度読み込んだページはバッファに保存されるので、同一ページ内の複数行を読む場合、最初の1回のI/O以降は不要になる。
改善理由:ランダムアクセスの処理時間〔同期データ入出力処理時間〕を短縮できる。
ランダムアクセス時にテーブルページが都度ディスクから読み込まれるのを防ぎ、同一ページの参照はバッファから行えるようになる。その結果、同期ディスクI/Oが大幅に減少し、処理時間を短縮できる。

【”オーソリ履歴”テーブル】
アクセス経路:表探索
処理:索引を使わずに先頭ページから順に全行を探索する。
データバッファを増やさない理由:順次アクセスになっているので、バッファを増やしても処理時間に影響しないから。
1. 「全行探索=順次アクセス」か?
- 全行探索(表探索 / 全表走査 = Full Table Scan)
→ 索引を使わず、テーブルの先頭から末尾まで全行を順に読む処理。 - このときの物理アクセスは 「順次アクセス(シーケンシャルアクセス)」 になります。
- ページ単位でディスクから読み込むため、ディスクのヘッドは連続的に動きます。
- ランダムアクセスのようにヘッドが飛び回ることがないので、効率が良い。
👉 つまり、全行探索は基本的に「順次アクセス」と考えてOKです。
2. なぜバッファを増やしても処理時間に影響しないのか?
ポイントは「参照の仕方」です。
- ランダムアクセスの場合
- 同じページを繰り返し参照する可能性がある。
- バッファに残しておけば、ディスクI/Oを減らせる → バッファ増加の効果が大きい。
- 順次アクセスの場合(全表走査)
- 先頭から最後まで 一度だけ順に読む。
- 既に読み終わったページを再参照することはない。
- よって、ページを長くバッファに保持しても意味がない。
- 必要なのは「読み込み中のページを一時的に置くバッファ」だけ。
👉 だから、バッファをいくら増やしても「再利用が発生しない」ため処理時間は変わらない。
まとめ
- 全行探索 = 順次アクセス(シーケンシャルスキャン)
- バッファを増やしても効果がない理由
→ 全行を一度きり順に読むだけで再参照がないから。
→ 順次アクセスの効率はディスク自体の転送速度に依存する。
設問1ー(3)


【”オーソリ履歴”テーブル】
<現状>
アクセス経路:表探索
<改善案>
アクセス経路:利用日列をキーとする副次索引の追加
オーソリ処理の処理時間が長くなる理由:一般的に、テーブルに索引を定義すると、検索時間は早くなるが、登録時間は長くなる。新たな行を追加する時に、索引も更新しなければならず、処理時間がかかる。したがって、『順次アクセスの処理時間に影響しないから』となる。
ポイント
副次索引を追加する効果
- 検索処理 → 索引経由で目的の行にアクセスできるため高速化される
- 登録・更新・削除処理 → 索引の内容を更新する必要があるため、その分オーバーヘッドが発生する
設問2
設問2ー(1)
設問2(1)は、課題1について、INSERT文の性能が良い理由を考える問題である。


課題1;月末近くのオーソリ処理のINSERT文の性能低下
現状処理内容:カード有効期限、与信限度額の釣果を判定し、結果を”オーソリ履歴”テーブルに挿入。
現状処理方法:最大100多重で処理される(〔カード決済システムの概要〕の2.オーソリ処理参照)
<案の比較>
【区分キー】
A・B:カード番号→異なるテーブルに100多重で処理される。
C:利用日→同じテーブルへの処理となり、更新待ちが発生する。

設問2ー(2)
設問2(2)は、課題2(将来懸念される利用明細抽出処理の処理時間の短縮)について、区分限定の表探索を行う場合の1ジョブが探索する区分数及びページ数の最小値を求める問題。


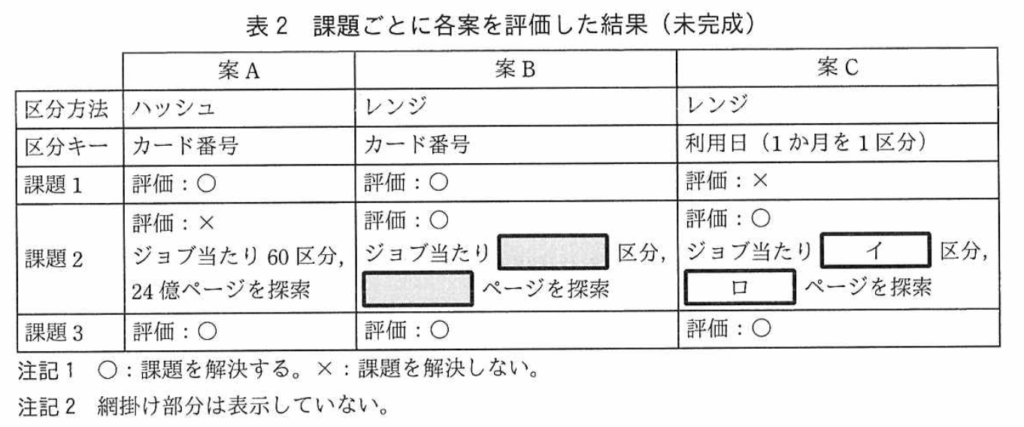

【利用明細抽出処理】
処理内容:1ヶ月分の利用明細の記録を”オーソリ履歴”テーブルから抽出しファイルに出力する。
案C・区分キー:利用日(1ヶ月を1区分)
空欄(イ):案Cのジョブ当たりの区分数→1(1ヶ月分の処理のため)
空欄(ロ):案Cのページ数→40,000,000(24億[ページ]/60[区分])
設問2ー(3)
設問2(3)は、課題2(将来懸念される利用明細抽出処理の処理時間の短縮)について、案A(区分方法;ハッシュ)ではカード番号にBETWEEN述語を追加しても改善効果が得られない理由を答える問題。


<案A>
区分方法:ハッシュ
区分キー;カード番号
処理:ハッシュ区分の場合、、ハッシュキーによりページを区分するため、レンジとは異なりカード番号順で区分されない。つまり、BETWEEN述語を利用するには、ハッシュキーで範囲を決める必要がある。したがって、『区分方法がハッシュでは、探索する区分を限定できないから』となる。
ポイント
- ハッシュ分割
- 行を「ハッシュ値」に基づいて均等にバラバラに振り分ける。
- 特定の「等値検索」には強い(=ある区分に必ず存在するので高速)。
- ただし、範囲検索(BETWEEN, >, < など)には弱い。 → 全区分をまたいで検索する必要がある。
- 範囲検索(BETWEEN述語)
- データが値の大小に従って連続していることを前提に効率化される。
- よって、範囲分割(Range Partitioning) と相性が良い。
- 組み合わせのミスマッチ
- ハッシュ分割 × 範囲検索 → 非効率(全区分スキャンが必要)。
- 範囲分割 × 等値検索 → 一応動くが、分割数が多いとどこにあるか判定コストがある。
つまり、
- 等値検索中心 → ハッシュ分割が有効
- 範囲検索中心 → 範囲分割が有効
設問2ー(4)
設問2(4)は、課題3(月初に行う”オーソリ履歴”テーブル再編成の処理時間を短縮すること)について、区分キーから案C(区分キー0;利用日)が案A・B(区分キー;カード番号)に比べて賽銭兵の効率が良いと考えられる理由を答える問題。


行追加と再編成については、〔RDBMSの主な仕様〕で確認することができる。


<状況整理>
区分キー;利用日→利用日ごとにページが分かれている。
行挿入時;新しいデータなので利用日ごとに追加されていく。
再編成時:利用日ごとのテーブルから主キー{カード番号、利用日、オーソリ連番}に並び替える。
したがって、『案Aと案Bの再編成では、全区分を参照しなければならないが、案Cの場合は利用日ごとの区分のため、1区分に纏まっており、1区分の参照で良いので、再編成の処理時間が短くなる』となる。
ポイントとしては、再編成時には、テーブルの構造により処理時間が変わる。参照する区分数が少なくなると処理時間も比例して短くなる。
✅ 得られるポイント(再編成関連)
- 区分方法によりテーブル構造が変わる
→ どの列をキーに区分するかで、データの「まとまり方」が変わる。 - テーブル構造により処理時間が変わる
→ データが分散していれば全区分を参照しなければならず、まとまっていれば対象区分だけで済む。 - 区分が少ない方が、読み込むデータ量(ページ数)が少ない
→ ページI/Oが減るので処理時間が短縮される。
✅ 再編成時に特に押さえておきたいポイント
- 再編成は基本的に「並び替え+断片化解消」処理
→ 主キー順や物理配置を揃えるために全データを読み込む必要がある。 - データの分布が「対象列に沿ってまとまっている」ほど効率が良い
→ 例:利用日ごとに追加される場合、利用日区分だと新旧データが固まり、再編成対象がシンプルになる。 - 区分数が増えると並列処理の効率は上がるが、再編成処理の参照コストは増える
→ 挿入性能と再編成性能はトレードオフになる場合がある。 - 再編成コストは「全件アクセスが必要か?一部区分で済むか?」で大きく変わる
→ 今回は「案Cは利用日単位で固まっているため一部区分で済む」がキーポイント。
✅ まとめると
- 区分方法によってデータのまとまり方が変わる。
- 再編成では「どのくらいの区分を参照する必要があるか」が処理時間を左右する。
- 再編成効率を考えると、対象業務の処理単位(今回なら利用日)と区分キーを揃えるのが有利。
設問3
設問3は、〔更新多重化〕について答える問題です。
設問3(1)

設問3(1)は、ジョブの多重度を増やしても、更新処理全体の処理時間を短くできない、ボトルネックはログである。その理由を答える問題。この時点での処理方法は下記のようになっている。
・”オーソリ履歴”テーブルの区分キー;{カード番号、利用日}、区分方法:レンジ
・区分毎のジョブで更新処理を多重化
・各区分を異なるディスクに配置し、データバッファを十分に確保(更新処理の多重化で競合しないように)


・データバッファはテーブル毎に確保される。
・ログ→ログバッファ(RDBMSに1つ)→ディスク(;ログ出力)
・ログ出力の契機
①ログバッファが一杯になる
②トランザクションがコミットまたはロールバックを行った
③あるテーブルのデータバッファが変更ページによって一杯になった
ログ出力処理は並列化されない(逐次化される)ので、ボトルネックになる。(データバッファはテーブル毎に1つあり、並列処理できるが、ログバッファはRDBMSに1つであり、逐次処理になる)
「ログバッファが一杯の場合、トランザクションのINSERT文、UPDATE文、DELETE文の処理は待たされる」と記載があるように、トランザクション処理が中断する。中断中は、ディスクへの出力(;ログ出力)が行われる。ログ出力が完了した後、トランザクションの各構文の処理が再開される。
「トランザクションがコミットまたはロールバックを行った」時にもログ出力が行われる。この場合、「トランザクションのコミットはログ出力の完了まで待たされる」とあるので、ログ出力が行われ、トランザクションのコミットはログ出力の完了まで待つことになる。
したがって、回答としては、下記のようになる。
『コミットはログ出力の完了まで待たされるから』
『ログ出力処理は並列化されないから』
『ログ出力処理は逐次化されるから』
『ログバッファが一杯だと更新が待たされるから』



✅ ボトルネックになる理由(要点)
- ログ出力処理は並列化できず逐次的に行われる
→ 各トランザクションがログ書き込み待ちになる。 - コミットはログ出力の完了を待たされる
→ コミット処理の完了=ログディスクへの永続化が保証されるまで進めない。 - ログバッファが一杯になると更新処理も待たされる
→ INSERT/UPDATE/DELETE が進めず、全体のスループットが落ちる。
✅ データバッファは並列化できる
- 各テーブルや区分ごとに「データバッファ」が確保されます。
- だから、テーブルのI/Oや検索・更新処理は並列に進められます。
✅ ログバッファはRDBMSに1つしかない
- ログは 全トランザクションで共通の仕組み を使います。
- もし複数の処理が同時にログを書き込もうとすると、ログの「整合性(順序)」が保証できなくなってしまいます。
(例:Aの更新がログに残っていないのに、Bのコミットだけログに出たら復旧できなくなる)
(補足)データバッファ経路とログバッファ経路の違い
✅ まとめ
データバッファ経路(並列可)
SQL更新 → データバッファ(テーブルごと)に反映 → (後で)非同期にディスクへ書き戻し
ログバッファ経路(直列処理)
SQL更新 → ログバッファ(RDBMSに1つ)に記録 → (条件に応じて即時)ディスクへ出力(順序保証が必要)
✅ データバッファ経路
- アプリケーションからSQL(INSERTなど)が発行される
- 該当するテーブルの データバッファ(キャッシュ) に更新が反映される
- ここは並列処理できる(テーブルごと・区分ごとにバッファがあるため)
- データバッファが一杯になったら、バックグラウンドで非同期にディスクへ書き戻される
- これを「チェックポイント処理」と呼ぶ
- バッファの更新は非同期なので、SQL実行直後にディスクI/O待ちするわけではない
👉 特徴:並列処理が効きやすい。多重化すればスループットは上がる。
✅ ログバッファ経路
- 同じ更新処理が ログバッファ(RDBMSに1つ) に書き込まれる
- 各SQLの更新内容は必ずログに残す必要がある
- ログバッファは1つなので 並列書き込みは不可(排他制御あり)
- 以下のタイミングで ログバッファ → ディスク(ログファイル) に出力される
- ログバッファが一杯になったとき
- コミットやロールバックをしたとき
- データバッファが更新ページで一杯になったとき(チェックポイント連動)
- ログ出力は直列処理
- ログは障害復旧の「唯一の証拠」なので、必ず順序を守ってディスクに記録しなければならない
- だから並列化できず、書き込み完了を待たされる
👉 特徴:直列処理しかできないため、ここが更新処理全体のボトルネックになる。
設問3(2)
設問3(2)では、更新処理の内、1,000行毎コミットから1行毎コミットで、更新処理の処理時間の内、何がどのように変わるかを考える問題。

コミット部分について整理する。
・ログ→ログバッファ(RDBMSに1つ)→ディスク(;ログ出力)
・ログ出力の契機
②トランザクションがコミットまたはロールバックを行った
・トランザクションのコミットはログ出力の完了まで待たされる
つまり、
①トランザクションがコミットされると、ログ出力を行う。
②ログ出力中は、トランザクションのコミットが待たされる。
回答について考えると、
1,000行から1行ごとのコミットになることで、コミットの回数が増加する(コミット数が1から1,000に増える)。よって、1,000回ログ出力を行う。
①からは、ログバッファはRDBMSに1つしかなく、逐次処理(並列処理不可)になるので、1,000回処理する時間がかかる。
②からは、1,000回ログ出力を行うので、その分のコミット待ちが発生する。
| コミット単位 | コミット回数 | ログ出力回数 | 待ち時間の影響 |
|---|---|---|---|
| 1,000行毎 | 1回 | 1回 | 少ない |
| 1行毎 | 1,000回 | 1,000回 | 大幅に増加 |
したがって、回答としては、
『ログ出力処理の待ち時間の合計が長くなる』
『コミット時の待ち時間の合計が長くなる』
設問3(2)のポイント整理
- RDBMSでのコミット後の処理
一般的なRDBMSでは、トランザクションのコミット後に次のような流れがあります:コミット要求 → ログバッファへの書き込み →<変更内容あり> ディスクへのログ出力 → 後続処理待ち(同期的にブロックされる場合あり)- ログ出力がディスクに同期的に行われる場合、コミット直後は後続処理が待たされます。
- 逆に、非同期で書き込む場合は、後続処理を待たずに次の処理が進むこともあります。
- コミット回数とパフォーマンスの関係
- コミットを頻繁に行う場合:
- 毎回ログ出力→処理待ちが発生する
- 結果として処理全体が遅くなる
- コミットを少なくする場合:
- ログ出力の待ち時間を減らせる
- 一括処理で効率よくトランザクションを進められる
- コミットを頻繁に行う場合:
- ポイント 「コミット→ログ出力→処理待ち」が発生する場合は、コミットを少なくした方が処理待ちがなくなる
- つまり、処理待ちがボトルネックになる場合は、まとめてコミットする方がスループットが上がる
- 逆に、トランザクションを長くしすぎると、障害発生時のロールバック範囲が大きくなるため注意が必要
まとめ
1. データバッファ(Data Buffer)について
- 役割:テーブルやインデックスのページをメモリ上に保持し、ディスクI/Oを減らすための領域です。
- 関係する処理:
- SELECT:データの読み込み(ページ入出力)に関係
- INSERT/UPDATE/DELETE:書き込み対象ページをバッファに読み込み、更新後にディスクへ反映
まとめ:データバッファは「テーブルやインデックスページへの読み書き」に関係します。
- CPU処理時間の考え方:
- ランダムアクセス:ページが分散しているため、CPUはI/O待ちが発生 → 逐次処理
- 順次アクセス:連続ページなので、I/OとCPU処理をある程度並列処理可能
2. ログバッファ(Log Buffer)について
- 役割:トランザクションの変更内容(INSERT/UPDATE/DELETE)を一時的に保持し、ディスクのトランザクションログに書き込むための領域
- 特徴:
- RDBMSにつき1つ
- 必ず逐次処理で書き込む(ログ順序を保証するため)
- コミット時にディスクへ同期書き込みされる(同期コミットの場合)
まとめ:ログバッファは「変更内容を安全に保存する」ための処理に関係します。
3. SQL実行から結果表示までの流れ
- SQL文実行
- パーサーが構文解析 → 実行計画作成
- ページ読み込み(データバッファ)
- データやインデックスページを必要に応じてバッファに読み込む
- 変更処理
- 変更あり(INSERT/UPDATE/DELETE):
- データバッファ上で更新
- ログバッファへ変更内容書き込み
- コミット後にログをディスクに同期書き込み(場合によっては待ち時間あり)
- 変更なし(SELECT):
- データバッファから読み出し → 結果返却
- 変更あり(INSERT/UPDATE/DELETE):
- SQL結果表示
4. ポイント
- データバッファ:テーブル・インデックスページの読み書き;テーブルごとの場合、並列処理可能
- ログバッファ:変更内容を安全に保存;RDBMSに1つの場合、並列処理不可
- RDBMS処理の流れ:
<変更あり>①SQL実行 → ②データバッファ(テーブルへの読込) →③ログバッファ(変更内容の保存) → ④結果表示
<変更なし>①SQL実行 → ②データバッファ(テーブルへの読込) →→ ③結果表示
DB処理の一連の流れ(最初から完了まで)を整理させてください。 ・SQL文の実行(ページ入出力処理(データバッファ)に関係する) データバッファとは、テーブルに格納されているデータへの処理? A:ランダム→逐次処理;CPU処理時間=SQL処理時間(SQL文の実行?)+入出力処理時間(ページ読み込み・更新?) B:順次→並列処理;CPU処理時間=QL処理時間(SQL文の実行?)と入出力処理時間(ページ読み込み・更新?)のどちらか高い方 ・変更内容の保存(ログバッファに書き込まれる) ・RDBMSに1つ ・更新内容の保存のため、逐次処理で確実に実施される つまり、SQL実行→データバッファへ入出力処理実施 →<A:変更内容あり>→ログバッファへ書き込みし、変更内容保存。→完了後、次のトランザクションがコミット。→全て終わるとSQL実行結果表示 →<B;変更内容無し>→SQL実行結果表示 ですか? 要するに、データバッファは、テーブル読み込み(ページ読み込み)の処理に関係する。 ログバッファは、変更内容保存(一部のSQL文;INSERT、UPDATE、DELETE)の処理に関係する。 経路としては、 <変更内容があるSQL文の場合>SQL文実行→テーブル読み込み(データバッファ)→ログバッファ→SQL結果表示 <変更がないSQL文の場合>SQL文実行→テーブル読み込み(データバッファ)→SQL結果表示 私の理解が正しいかどうか教えてください。一連の処理作業で不足している点も教えてください。

