
出題要旨
・性能測定の目的にあったSQL文の設計能力
・アクセス経路による性能を見極める能力
・性能測定結果から適切に分析できる能力
設問2

設問2は、〔SELECT文の処理時間測定〕に関して、処理時間を答える問題。
【f】〜【k】の問題(非同期データ入出力処理)
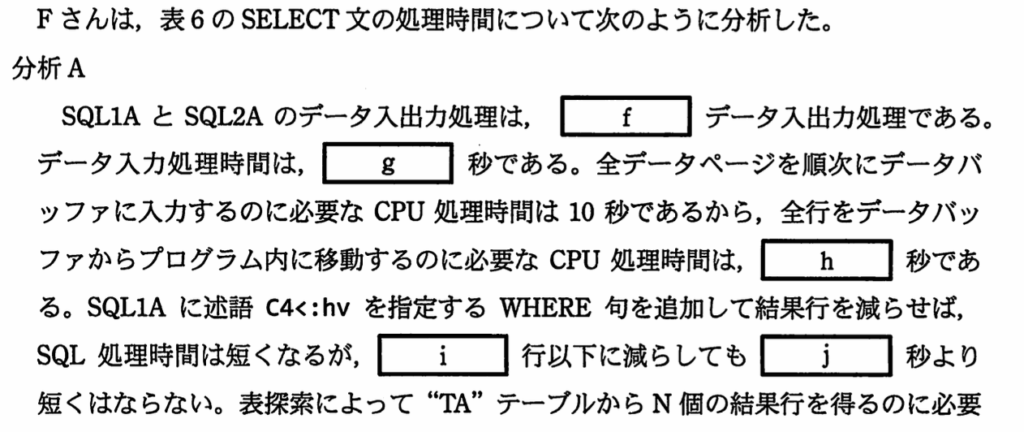
【f】
データ入出力方式について答える。
対象のSQL1AとSQL2Aの仕様は、表4「測定用SQL文の仕様」を確認すると、次のようになっている。
・SQL1x;「表探索によって、全データページを読み込む。全行が結果行である」
・SQL2x;「表探索によって、全データページを読み込む。結果行はない」
〔RDBMSの主な仕様〕4.で「表探索は、索引を使わずに先頭データページから全行を探索」とある。
また、RDBMSのデータ入出力処理とログ出力処理に関する仕様の3.において、「ディスクに対して、データページを順次に入出力する場合、〜中略〜この場合のデータ入出力処理を非同期データ入出力処理と呼び」とある。
よって、SQL1x・2xは表探索による全行探索となるので、『非同期』データ入出力処理になる。
【g】
非同期データ入力処理時間について答える問題。
まず、データ入出力処理については、「入力」と「出力」の時間から構成される。
表6「SELECT文の処理時間の一部(秒)」から、次のようになっている。
<SQL1A>SQL処理時間;2,010|CPU処理時間;2,010
<SQL2A>SQL処理時間;1,000|CPU処理時間;10
RDBMSのデータ入出力処理とログ出力処理に関する仕様の3.において、
「SQL処理時間=MAX(CPU処理時間,データ入出力処理時間)」とある。
よって、
<SQL1A>データ入出力処理時間;不明(CPU処理時間がSQL処理時間となっているため)
<SQL2A>データ入出力処理時間;1,000(SQL処理時間が1,000となっており、CPU処理時間とデータ入出力時間の大き方を採用するため)
となり、データ入出力時間は、「1,000」秒であると分かる。
さらに、データ入出力時間は、「入力」と「出力」により構成されるので、ここから「入力」処理時間について計算する。
〔SELECT文の処理時間の測定〕で、「SELECT文の結果行は外部ファイルに出力していない」とある上での表6「SELECT文の処理時間の一部(秒)」なので、表6にはデータ出力時間は含まれておらず、「0」秒となる。
したがって、データ入出力時間;1,000秒、データ出力時間;0秒となるので、データ入力時間は『1,000』秒となる。
【h】
全行をデータバッファからプログラム内に移動するのに必要なCPU処理時間についてである。
分析Aの中で、「全データページを順次にデータバッファに入力するのに必要なCPU処理時間を10秒」とあり、CPU処理時間も、「入力」と「出力」に分かれると考えられ、CPU入力処理時間は10秒と分かる。
SQL1AのCPU処理時間;2,010秒で、CPU入力処理時間;10秒なので、CPU出力処理時間;2,000秒と計算できる。
ここで、SQL1A・2AのCPU入力処理時間は、表4「測定用SQL文の仕様」の「表探索によって、全データページを読み込む」という仕様は同じなので、CPU入力処理時間も共通して10秒かかる。
また、SQL2AのCPU出力処理時間は、表4「測定用SQL文の仕様」の「結果行はない」から、0であることが分かる。
したがって、全行をデータバッファからプログラム内に移動するのに必要なCPU処理時間は、『2,000』秒となる。
①全データページを順次にデータバッファに入力する時間;10秒(問題文より)
②全行をデータバッファからプログラム内に移動するのに必要な処理時間;2,000秒【h】
(CPU処理時間;2,010秒)ー(全データページを順次にデータバッファに入力する時間;10秒)
③【データ出力処理時間】
SQL1A;0(SELECT文の結果行は外部ファイルに出力しない)
SQL2A;0(SQL2Aでは出力がない)
④【データ入力処理時間】【g】
データ入力処理時間;1,000秒(SQL2AのSQL処理時間が入る)



【i】〜【k】の問題

【i】【j】は、結果行を減らしてSQL時間を減らす問題である。
結果行が変わることにより、影響があるのは、データ出力処理時間である。しかし、現在0秒であり影響はない。
一方、入力処理時間は、1,000秒であり、入力処理行は変わらないので、1,000秒はかかる。
【j】入力処理行数(;20,000,000行)は変わらないので、出力を0にしても入力処理の時間はかかってしまい、少なくとも1,000秒はかかる。
現在、SQL処理時間=MAX(①CPU入出力処理時間,②データ入出力処理時間;1.000秒)である。
よって、①CPU入出力処理時間が、1,000秒以下の時、最速1,000秒であるが、1,000秒未満でも②データ入出力処理時間;1,000秒がかかり、ボトルネックとなる。
つまり、1,000秒間、目一杯でCPU入出力処理を行うことができる。
CPU入力処理時間は、すでに10秒と分かっているので、CPU出力処理時間を計算して、
CPU出力処理時間;990秒(CPU処理時間;1000秒ーCPU入力処理時間;10秒)。
【i】SQL時間は1,000秒かかるので、CPU処理時間が1,000秒の時、同時並行処理で最短時間で処理できる。
・CPU入力処理時間;10秒
・CPU出力処理時間;990秒(CPU処理時間;1000秒ーCPU入力処理時間;10秒)
・20,000,000行を 2,000秒で処理したいので、1行あたり0.0001秒で処理すれば良いことになる。
・残りのCPU出力処理時間で、処理を実行すると、990秒÷0.0001秒=9,900,000行が実行できるが、これ以上減らしても、SQL1Aの2,000秒の方が大きいので短くできない。
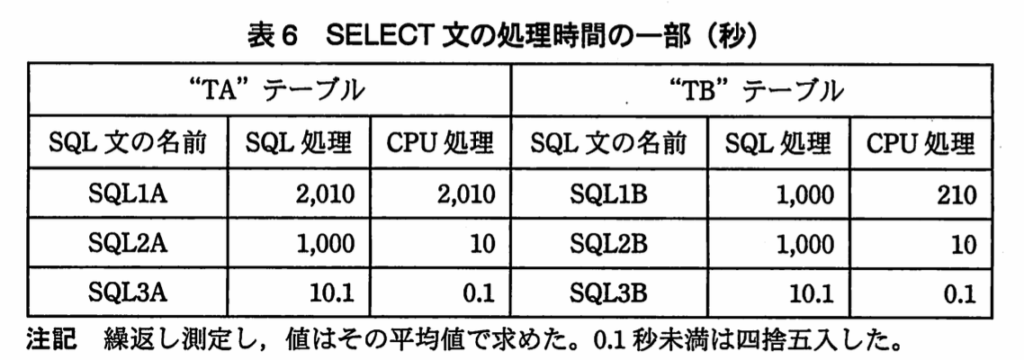
【k】1,000,000ページ

ポイント
SQL処理時間=①CPU処理時間+②データ入出力処理時間
①CPU処理時間=①A;データ入力処理のCPU処理時間+①B;データ入出力処理のCPU処理時間
①CPU処理時間;SQL実行にかかる時間。SQLの演算時間。CPU処理が終わるとSQLの結果が得られる。
①A;データ入力処理のCPU処理時間;全データページを順次にデータバッファに入力するのに必要なCPU処理時間
①B;データ出力処理のCPU処理時間;全行をデータバッファからプログラム内に移動するのに必要なCPU処理時間
②データ入出力処理時間=②A;データ入力処理時間+②B;データ出力処理時間
②データ入出力処理時間;ディスクに対する入出力処理の時間。データログの保存に関わる。
②Aデータ入力処理時間;ディスクへの入力処理時間
②Bデータ出力処理時間:ディスクからの出力処理時間
<トランザクションの処理フロー>
⬛︎非同期処理の場合;SQL実行後、CPU処理とデータ入出力処理が並行して行われる。
SQL実行→SQL処理(CPU処理演算)→SQL結果処理
SQL実行→「ログの保存(ディスクへの書き込み)→ログからの出力(ディスクからの書き出し)」
⬛︎同期処理の場合;SQL実行後、CPU処理→データ入出力処理が順次で行われる。
SQL実行→SQL処理(CPU処理演算)→SQL結果処理
→「ログの保存(ディスクへの書き込み)→ログからの出力(ディスクからの書き出し)」
🔸 SQL処理時間の構成要素まとめ
| 区分 | 内容 | 主な処理 | 具体例(秒) |
|---|---|---|---|
| ① CPU処理時間 | SQLの演算処理に要する時間 | ・演算・条件評価・データバッファ上の処理 | SQL1A:2,010SQL2A:10 |
| ├①A:データ入力処理のCPU時間 | データページを順次バッファへ読み込む | 全データページの読み込み | 10 |
| └①B:データ出力処理のCPU時間 | バッファからプログラム内へデータ移動 | 結果行生成・取得 | 2,000 |
| ② データ入出力処理時間 | ディスクI/Oに要する時間 | ・データの読み込み(入力)・データの書き込み(出力) | SQL2A:1,000 |
| ├②A:データ入力処理時間 | ディスク→バッファ(読み込み) | 表全体の読み込み | 1,000 |
| └②B:データ出力処理時間 | バッファ→ディスク(書き込み) | 結果行の外部出力 | 0 |
| SQL処理時間 | RDBMSで計測される総処理時間 | MAX(①CPU処理時間,②データ入出力処理時間) | SQL1A:2,010SQL2A:1,000 |
🔸 同期処理と非同期処理の違い
| 項目 | 同期処理 | 非同期処理 |
|---|---|---|
| 処理の流れ | CPU処理 → I/O処理を順番に実行 | CPU処理とI/O処理を並行実行 |
| SQL処理時間の算出 | 加算(CPU+I/O) | **最大値(MAX)**を採用 |
| メリット | 処理の順序が明確で制御しやすい | 高速化(CPUとI/Oが重ならない時間を削減) |
| デメリット | I/O待ちの間、CPUが遊ぶ | 処理の同期が複雑になる |
| H23設問の対象 | ― | ✅ 非同期処理 |
🔸 まとめポイント
| 覚えるべき式 | 内容 |
|---|---|
| SQL処理時間=MAX(CPU処理時間,データ入出力処理時間) | 非同期処理の場合 |
| SQL処理時間=CPU処理時間+データ入出力処理時間 | 同期処理の場合(参考) |
【l】〜【n】の問題(同期データ入出力処理)

【l】表4からSQL3Aは非クラスタ索引であることが分かる。
〔RDBMSの主な仕様〕から、非クラスタ索引は、ランダムな索引であることが分かる。
「RDBMSのデータ入出力処理とログ出力処理に関する仕様」から、データページをランダムに出力する場合のデータ入出力処理を「同期データ入出力処理」と呼ぶことが分かる。
したがって、【同期】となる。
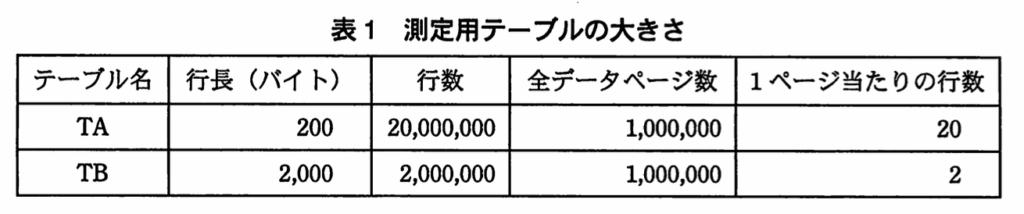
【m】★並び順がランダムな場合、読み込む最大のページ数は、行数になる。
つまり、毎行読み込む度に、ページが変わる場合が最大となる。
表4のSQL3xの仕様の「結果行を1,000行得る」という記載から、行数;1,000=最大ページ数となる。
【n】SQL3Aを実行した最大のアクセスページが入る。1ページあたり1件検索したケースが最大値と考えられるため、結果行の行数である’N’が入る。
<ポイント>
・非クラスタ索引;ランダム読み込み
★並び順がランダムな場合、読み込む最大のページ数は、行数になる。
設問3
設問3(1)

ア:C2 BETWEEN 1 AND 100
理由:・アクセス経路によって行を更新する順番が異なるから。
・索引TAX1と索引TAX2とでは行を更新する順番が異なるから。
<条件>
・同じ行の同じ列に対して、更新処理を行うSQL
・SQL5Aとは異なる順番でデータアクセスが行われるようなSQL
設問3ー(2)

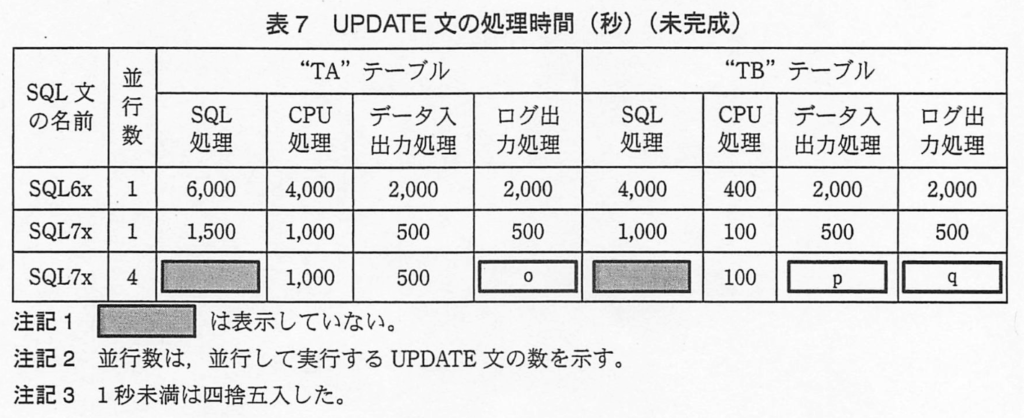
【o】CPU時間、データ入出力時間が共に4分の1になるが、ログファイルは1個しかないので、SQL6Aと同じになるので、”TA”テーブルに対するSQL6xのログ出力処理時間と同じ”2,000”になる。
【p】”TB”テーブルに対して、SQL7xを4区分並行して全行更新した場合のデータ入出力処理時間
<SQL7B(並行数=4)>
行数N=2,000,000/4=500,000
入力データページ数=1,000,000/4=250,000
出力データページ数=1,000,000/4=250,000
入出力データページ数=500,000
ログページ数=1,000,000×2=2,000,000
T3CPU時間=0.2ms/行×2,000,000行=400秒
T3のデータ入出力処理=1ms/ページ×500,000ページ=500秒
T3のログ出力時間=1ms/ページ×2,000,000ページ=2,000秒
【q】”TB”テーブルに対して、SQL7xを4区分並行して全行更新した場合のログ出力時間
設問3(3)

記号;BまたはC
理由:<B;ログバッファがログページによって一杯になった場合>
・高々1,000行を更新してコミットするから
・ログバッファが一杯になる前にコミットするから
<C;データバッファが、変更データページによって一杯になった場合>
・高々1,000行を更新してコミットするから
・データバッファが一杯になる前にコミットするから
ポイント
データバッファ vs ログバッファ
| 項目 | データバッファ(Data Buffer) | ログバッファ(Log Buffer) |
| 1. 役割 | データI/Oの高速化。ディスク上のデータページを一時的にメモリに格納し、アクセス速度を向上させる。 | トランザクションの永続化を保証。更新情報(REDO/UNDOログ)をディスクに書き込む前に一時的にメモリに溜める。 |
| 2. 格納内容 | テーブルデータ、索引データなどのデータページ。 | トランザクションログ(データの変更内容やCOMMIT/ROLLBACKの情報)。 |
| 3. この問題での関わり | SQL1A/2Aの表探索により、ディスクからデータページがここに読み込まれる。設問 g や h の計算の起点となる。 | SELECT文では、通常、関わらない(更新がないためログの書き込みは発生しない)。UPDATE/INSERT/DELETEで重要となる。 |
| 4. まとめ(一言) | 「データ」の高速な読み書き用メモリ | 「更新履歴」の一時保管用メモリ |
RDBMSの処理フロー
| 処理ステップ | 処理内容 | 変更あり(INSERT / UPDATE / DELETE) | 変更なし(SELECTなど) |
|---|---|---|---|
| ① SQL実行 | SQL文を解析し、実行計画を作成して処理開始 | 構文解析・最適化を行い実行 | 同左 |
| ② データバッファ処理 | テーブル・インデックスページをメモリ上(データバッファ)に読み込む | 読み込み後、対象データを更新または追加 | 読み込みのみ(変更なし) |
| ③ ログバッファ処理 | 変更内容を一時的に保存(ログバッファ) | 更新内容をログに記録し、コミット時にディスクへ同期書き込み | 処理なし |
| ④ コミット / ロールバック | トランザクションの確定または取消 | コミット時にログをディスクに出力、データを永続化 | コミット不要(読み取りのみ) |
| ⑤ 結果表示 | 実行結果をクライアントへ返す | 更新結果または完了メッセージを返す | 検索結果を返す |
バッファヒット率の「高い・低い」がシステムに与える影響
| バッファヒット率 | 状態 | システムへの影響 |
| 高い(理想:90%以上) | 多くのデータがメモリ上に存在している。 | ✅ レスポンスタイムの向上:データアクセスが高速化し、SQLの処理時間が短縮される。 ✅ CPU負荷の低減:ディスクI/O処理やデータ転送処理が減るため、CPUの負荷が下がる。 |
| 低い(問題:80%以下) | 頻繁にディスクへのアクセスが発生している。 | ❌ パフォーマンスの劣化:ディスクI/Oがボトルネックとなり、SQLの実行が遅延する。 ❌ ディスクI/O待ちの増加:システム全体の待ち時間が増え、同時実行性が低下する。 |

